Nuförtiden är det nästan omöjligt att hitta en webbapplikation som inte använder någon form av användarautentisering. Slutanvändare måste vanligtvis gå igenom en inloggningsprocess för att få tillgång till en apps alla funktioner och skyddade resurser.
Men hur användarautentisering implementeras varierar beroende på applikationens specifika krav och typ Detta gäller både för traditionell autentisering med användarnamn och lösenord samt den som implementeras via ett federerat autentiseringsprotokoll, till exempel OpenID Connect.
I det här blogginlägget ger vi en översikt över sessionsbaserade och tokenbaserade implementeringsmetoder som används vid traditionell autentisering. Vi kommer att belysa skillnaderna mellan användarsessioner och tokens för att upprätthålla autentiseringsstatus och visa hur de tillgodoser olika applikationsarkitekturer.
Dessutom kommer vi att täcka de två primära autentiseringsflödena som definieras av OpenID Connect: Authorization Code Flow och Proof Key for Code Exchange (PKCE) Flow. Vi diskuterar hur man väljer rätt flöde beroende på applikationstyp och införlivar den användarinformation som tas emot från OpenID Provider i en befintlig autentiseringslogik, antingen sessions- eller tokenbaserad.
Huvudmålet är att identifiera nyckelfaktorer att ta hänsyn till när man väljer mellan sessionsbaserad och tokenbaserad autentisering. Vi kommer också att utforska hur OpenID Connect-flöden effektivt kan integreras i en applikation med autentiseringsmekanismer som redan finns på plats.
1. Autentisering med användarlegitimation
Användaruppgifter är ett vanligt sätt för webbapplikationer att verifiera användaridentitet. Med denna metod tillhandahåller användarna en unik kombination av ett användarnamn och ett lösenord för att få tillgång till skyddade resurser och data i applikationen. Autentiseringsprocessen innebär att de angivna uppgifterna valideras mot användardata som finns lagrade i applikationens databas.
Från registrering till autentisering: en mekanism för att lagra en användares autentiseringsstatus
Låt oss fundera på vad som händer när en ny, oregistrerad användare interagerar med en applikation för första gången.
Vid denna första interaktion kommer användaren att gå igenom en registreringsprocess och ange sitt användarnamn och lösenord på applikationens registreringssida. När användaren har skickat in sina uppgifter skickas informationen till servern och lagras i applikationens databas. Detta görs vanligtvis via en API-slutpunkt eller kod på serversidan som hanterar användarregistreringsprocessen.
Nästa gång den registrerade användaren begär åtkomst till en skyddad resurs i applikationen måste han eller hon bevisa att han eller hon har de nödvändiga åtkomsträttigheterna. För att undvika att be användaren om inloggningsuppgifter vid varje begäran är det nödvändigt att implementera en mekanism för att lagra användarens autentiseringsstatus över flera HTTP-begäranden. Detta beror på HTTP-protokollets statslösa natur, där varje begäran behandlas oberoende och inte har tillgång till information från tidigare begäranden.
De två mekanismer som vanligen används för detta ändamål är användarsessioner och bearer tokens. Utvecklare väljer mellan de två (eller implementerar en kombination av båda) baserat på vilken typ av applikation de arbetar med, säkerhets- och användbarhetsöverväganden och personliga preferenser.
Användarsessioner och cookies
Termen "användarsession" avser en serie användarinteraktioner med applikationen under en given tidsram. En session innehåller information om autentiserade användare och innehåller vanligtvis ett unikt sessions-ID, inloggnings- och utgångstider samt andra relevanta data.
Sessioner genereras och lagras på servern, vilket gör att servern kan hålla reda på och auktorisera användarens förfrågningar. När en session har skapats sätter servern en cookie som innehåller sessions-ID:t och skickar den till webbläsaren. När cookien har lagrats kommer webbläsaren att inkludera den i alla ytterligare förfrågningar tills den löper ut eller användaren loggar ut. Servern använder cookien för att identifiera den aktuella användarsessionen.
Användarsessioner och cookies har funnits länge och används fortfarande i stor utsträckning, särskilt i traditionella webbapplikationer där autentisering ofta implementeras på serversidan.
Bearer-tokens
En annan vanlig mekanism för att hantera användarautentisering är användningen av "bearer tokens". Det finns andra tokenformat, men JSON Web Tokens (JWT) har blivit den rådande standarden för tokenbaserad autentisering.
En "token" är en kryptografiskt signerad datafil som innehåller information om den autentiserade användaren och dennes åtkomstbehörigheter. När en användare loggar in skapar servern en bearer-token och skickar den till klienten. Klienten sparar sedan token och inkluderar den i varje efterföljande begäran som den skickar till servern. Till skillnad från vad som gäller för en användarsession behöver servern bara verifiera tokenens giltighet i stället för att lagra den i en databas. Detta är möjligt eftersom token i sig innehåller all information som behövs för att bevisa dess giltighet.
Med tokenbaserad autentisering behöver servern inte lagra varje användares autentiseringsstatus, vilket i slutändan minskar den mängd information som behöver lagras på servern.
Bearer-tokens är ett populärt val för moderna Single-Page Applications (SPA) där autentiseringen ofta sker på klientsidan och där hastighet, användarupplevelse och skalbarhet ofta prioriteras.
Med denna förståelse för sessioner och tokens kan vi gå vidare till att skapa en mer komplett bild av sessionsbaserade och tokenbaserade autentiseringsflöden.
Sessionsbaserad autentisering
Sessionsbaserad autentisering fungerar på ett tillståndsmässigt sätt. Det innebär att en session måste sparas på både server- och klientsidan. Servern håller reda på aktiva användarsessioner och lagrar dem i minnet eller i en databas, och webbläsaren har sessions-ID:t i en cookie.
Flödet i den sessionsbaserade autentiseringen är som följer:
- Användaren anger sina inloggningsuppgifter i applikationens inloggningsformulär. När formuläret har skickats skickar webbläsaren en POST-begäran till servern med formulärets inmatning.
- Servern verifierar användarens uppgifter, t.ex. genom att kontrollera dem mot en databas med auktoriserade användare. Om uppgifterna stämmer skapar servern en användarsession med ett unikt sessions-ID och lagrar det i en databas.
- Servern returnerar sedan sessions-ID:t till webbläsaren, vanligtvis genom att inkludera en Set-Cookie header i svaret som innehåller en cookie med sessions-ID:t.
- Cookien med sessions-ID:t lagras i webbläsaren.
- Från och med nu kommer webbläsaren, varje gång den här användaren begär en sida, att inkludera en cookie med sessions-ID i varje begäran som skickas till servern.
- Servern tar emot begäran och kontrollerar sessions-ID:t.
- Om sessions-ID:t är giltigt svarar servern med den begärda resursen.
- När användaren loggar ut förstörs sessionen på servern och sessionskakan raderas från webbläsaren.
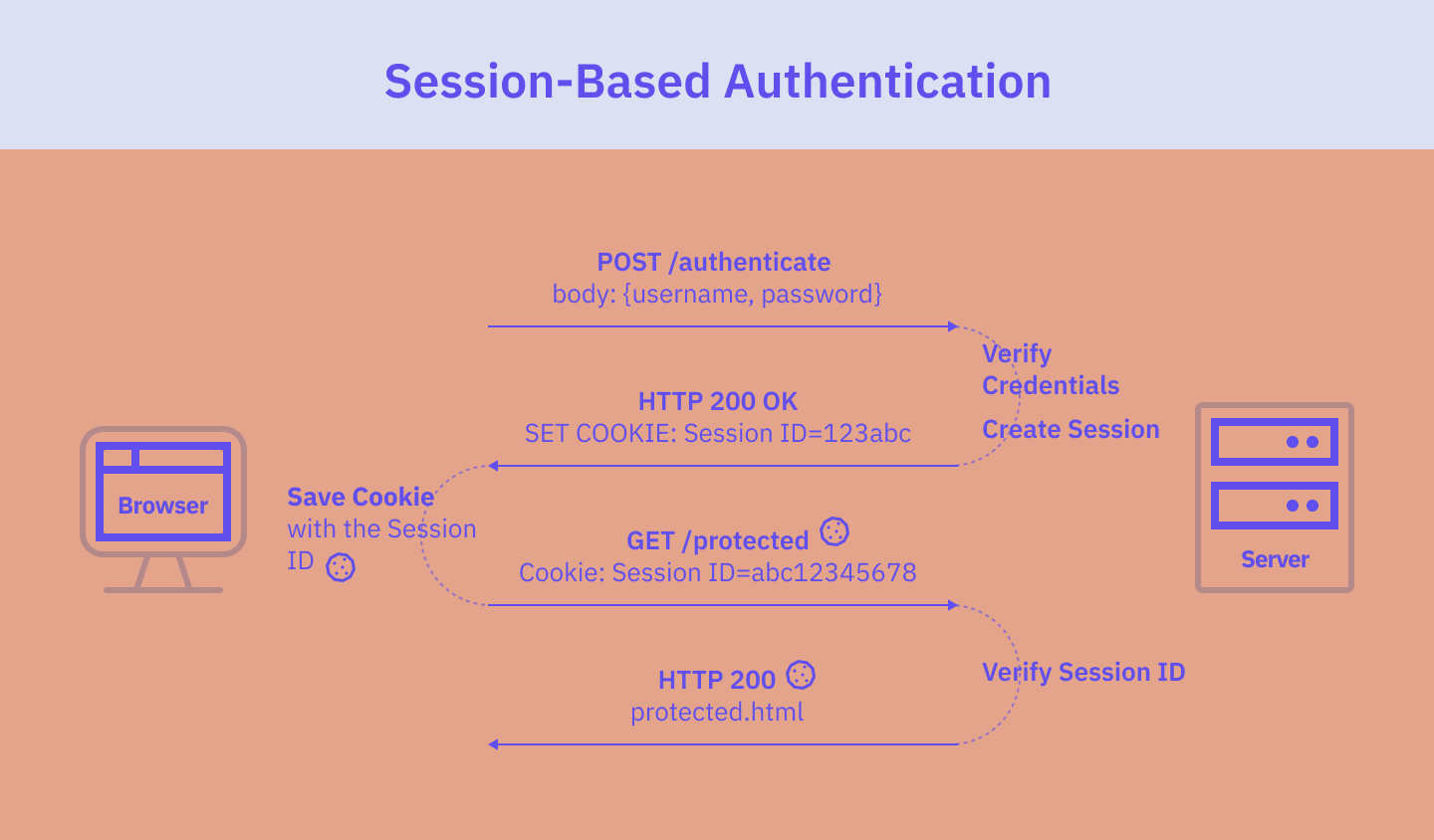
Sessionsbaserad autentisering används fortfarande ofta och har sina fördelar. Den fungerar mycket bra i en traditionell server/webbläsare-modell men kanske inte är idealisk för moderna webbapplikationer som kräver frekventa datautbyten mellan klienten och servern.
Tokenbaserad autentisering
I och med ökningen av Single-Page Applications och API:er har tokenbaserad autentisering blivit alltmer populär. Detta tillvägagångssätt bygger på användning av tokens för användarautentisering och fungerar på ett statlöst sätt. Till skillnad från sessionsbaserad autentisering eliminerar tokenbaserad autentisering behovet av att servern håller reda på de utfärdade tokens eller inloggade användare. Istället kontrollerar servern bara giltigheten hos de tokens den tar emot.
Autentiseringsflödet för tokenbaserad autentisering är som följer:
- Användaren anger sina inloggningsuppgifter i applikationens inloggningsformulär. Klienten skickar användarens autentiseringsuppgifter till servern i en POST-begäran.
- Servern verifierar användarens uppgifter genom att kontrollera dem mot en databas och genererar en bärartoken. Bearer-token innehåller information som användarens identitet och eventuella relevanta behörigheter eller roller.
- Servern skickar tillbaka token till klienten.
- Klienten tar emot token och lagrar den lokalt för att kunna använda den vid senare förfrågningar om skyddade resurser. I webbläsarbaserade applikationer lagras token vanligtvis i localStorage eller sessionStorage. I inbyggda mobilapplikationer lagras den i den lämpliga lagring som erbjuds av operativsystemet.
- Klienten skickar token tillsammans med varje efterföljande begäran till servern, vanligtvis i HTTP-begärans auktoriseringshuvud:
Authorization: Bearer <token> - Servern kontrollerar giltigheten och auktoriseringen av token vid varje begäran.
- Om token är giltig auktoriserar servern begäran.
- När en användare loggar ut förstörs token på klientsidan. Ingen interaktion med servern krävs.
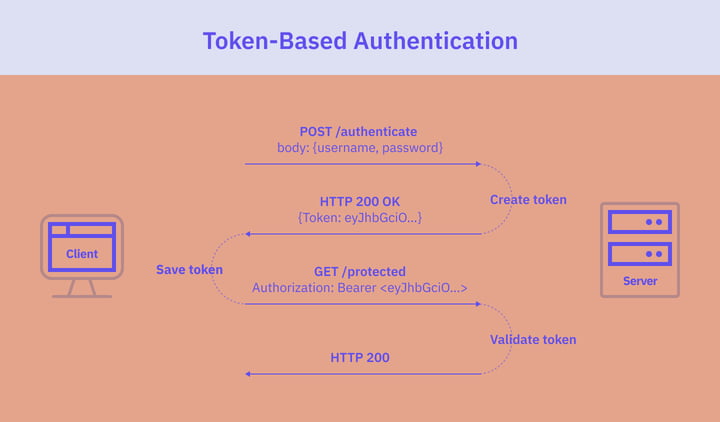
Tokenbaserad autentisering har flera fördelar, bland annat en smidigare användarupplevelse, minskad arbetsbelastning för servern samt bättre skalbarhet och prestanda tack vare att den är statslös. Den medför dock vissa säkerhetsproblem i samband med användningen av tokens, med tanke på de känsliga uppgifter som de innehåller.
Att välja rätt tillvägagångssätt
Användningen av sessioner kontra tokens vid användarautentisering är ett mycket omdiskuterat ämne.
Vissa utvecklare föredrar sessioner och cookies på serversidan: en tillförlitlig metod som passar väl in i den fortfarande utbredda traditionella arkitekturen för webbapplikationer. Andra väljer tokens, eftersom de kan ge en bättre användarupplevelse, hjälper till att undvika komplexiteten kring domänöverskridande cookies och fungerar utmärkt i moderna SPA:er och mobila applikationer.
För en uttömmande sammanfattning av fördelar och överväganden när man väljer mellan sessions- och tokenbaserad autentisering är den här artikeln en bra resurs.
Ett annat genomförbart tillvägagångssätt är en kombination av både sessioner på serversidan och tokens. En användare kan t.ex. autentiseras via en token på klientsidan, medan servern verifierar användarens autentiseringsstatus med en session på serversidan.
Sammantaget finns det inga universella regler när det gäller att välja den lämpligaste autentiseringsimplementeringen. Valet beror till stor del på de specifika behoven och kraven för varje applikation och applikationsarkitekturen. Om de implementeras med bästa säkerhetspraxis och användbarhetskrav i åtanke kan både sessioner och tokens (eller en kombination av dessa) ge tillräckliga skyddsnivåer och en användarvänlig autentiseringsmekanism.
2. Autentisering med OpenID Connect
Den federerade identitetsmodellen erbjuder ett övertygande alternativ till traditionell autentisering med användarnamn och lösenord.
Genom att använda ett federerat autentiseringsprotokoll, till exempel OpenID Connect (OIDC), kan utvecklare effektivisera autentiseringsprocessen och ge användarna ett bekant och bekvämt sätt att få tillgång till applikationer genom att logga in med en extern identitetsleverantör. Användare kan t.ex. logga in med sina befintliga Google- eller Facebook-konton eller med nationella eID: er.
OpenID Connect: att välja mellan Authorization Code Flow och PKCE
OpenID Connect definierar flera autentiseringsflöden som beskriver hur klientapplikationen ska interagera med en OpenID Provider.
Låt oss jämföra de två OIDC-flöden som ofta används och rekommenderas för användarautentisering: Authorization Code Flow och PKCE-flödet (Proof Key for Code Exchange).
Båda innebär att användare delar sina referenser med en OpenID Provider. I båda fallen utfärdar OpenID Providern en token som representerar användaren. De två flödena är dock utformade för att fungera bäst i olika applikationstyper.
Flödet för auktoriseringskod är avsett för traditionella webbapplikationer som har en komponent på serversidan och som kan lagra en klienthemlighet på ett säkert sätt. Det här flödet innebär att den auktoriseringskod som erhålls från OpenID Provider byts mot en token. För att utföra utbytet av kod mot token presenterar klientapplikationen auktoriseringskoden tillsammans med en klienthemlighet för att begära en token. Klienthemligheten är en konfidentiell identifierare som endast är känd av klientapplikationen och OpenID Providern.
PKCE-flödet (eller Authorization Code Flow + PKCE) är en utvidgning av Authorization Code Flow och kräver också kod-för-token-utbyte. Men i stället för en klienthemlighet introducerar PKCE-flödet en kodverifierare (en engångshemlighet som skapas av klientapplikationen och som kan verifieras av OpenID Provider) och en kodutmaning(en hashad och kodad version av kodverifieraren). Under kod-för-token-utbytet presenterar klientapplikationen auktoriseringskoden tillsammans med kodverifieraren. OpenID Provider kommer endast att fortsätta med tokenutbytet om denna kodverifierare matchar den ursprungliga kodutmaningen som skapats av klientapplikationen. Kombinationen av kodutmaning och kodverifierare i PKCE Flow säkerställer att även om auktoriseringskoden fångas upp under överföringen kan den inte bytas ut mot en token av en obehörig part.
PKCE Flow är särskilt utformat för att autentisera användare av inbyggda eller mobila applikationer. Det anses vara bästa praxis i native- och enkelsidiga applikationer som inte har något sätt att lagra en klienthemlighet på ett säkert sätt. PKCE Flow kan också vara ett bra val för andra typer av applikationer eftersom det kan skapa en smidigare användarupplevelse i vissa situationer. Till exempel i applikationer som har en SPA-klient ansluten till en server fungerar PKCE Flow bäst eftersom autentiseringsprocessen löses på klientsidan.
Nu när vi har utforskat hur de två OIDC-autentiseringsflödena passar bäst för olika applikationsarkitekturer, låt oss diskutera deras integration i en klientapplikation som redan har autentiseringslogik på plats.
Kort sagt: För sessionsbaserad autentisering rekommenderar vi att du använder Authorization Code Flow. Detta flöde passar väl in i traditionell webbapplikationsarkitektur och ger en hög säkerhetsnivå om applikationen har en komponent på serversidan som kan lagra en klienthemlighet på ett säkert sätt.
PKCE-flödet är å andra sidan ett logiskt val för den tokenbaserade autentiseringsmodellen på klientsidan, som ofta implementeras av inbyggda applikationer eller SPA:er. PKCE Flow ger ytterligare säkerhet för applikationer som antingen inte har ett säkert sätt att hålla en klienthemlighet eller har specifika krav relaterade till användarupplevelsen.
Den korta tabellen nedan ger en sammanfattning:
|
Sessionsbaserad autentisering |
Token-baserad autentisering |
Hybridmetod som kombinerar sessioner och tokens |
|
Flöde för auktoriseringskod |
PKCE-flöde rekommenderas |
PKCE Flow mest sannolikt, men det är möjligt att använda båda |
Anslutning av JWT-utdata till en bearer-token eller användarsession
När OIDC-flödet har slutförts och klientapplikationen tar emot JWT-token från OpenID Provider kan den antingen använda token direkt eller extrahera och använda informationen i JWT-anspråken. Det sätt på vilket klientapplikationen implementerar autentisering avgör hur JWT-utdata hanteras.
Sessionsbaserad autentisering och OIDC
Som nämnts innebär sessionsbaserad autentisering att ett unikt sessions-ID genereras inom applikationen och lagras i en databas.
När du utnyttjar användarinformationen som erhålls genom OIDC-auktorisering är ett alternativ att lagra JWT i användarsessionen. Alternativt kan du extrahera specifik information från JWT och länka den till sessionen för framtida referens.
I båda fallen kommer sessions-ID:t att användas för att associera efterföljande förfrågningar från samma användare med den lagrade sessionsinformationen.
Tokenbaserad autentisering och OIDC
Med tokenbaserad autentisering kan du antingen använda den JWT som utfärdats av OpenID Provider som din egen bearer-token eller låta din backend generera en ny bearer-token baserat på den JWT som mottagits från OIDC-autentisering. Det första alternativet är det vanligaste, men det finns vissa situationer där det är mer lämpligt att generera en ny bearer token. Till exempel:
- Om din klientapplikation redan förlitar sig på ett specifikt format för bearer token för sin befintliga autentiseringslogik, kan härledning av en ny bearer token bidra till att säkerställa kompatibilitet.
- På samma sätt, om din applikation interagerar med externa tjänster och API:er som har specifika krav på tokenformatet, måste du utfärda en ny bearer-token som överensstämmer med dessa.
- Att utfärda en ny bearer token ger mer flexibilitet, så att du kan anpassa token efter din applikations behov (t.ex. genom att inkludera ytterligare anspråk eller metadata).
- Att generera en ny innehavartoken ger dig mer kontroll över tokenens livscykel och kan vara nödvändigt om du har specifika krav för tokenens utgång och återkallelse.
Sammanfattning
Vid implementering av användarautentisering har utvecklare möjlighet att välja mellan sessionsbaserade och tokenbaserade metoder.
Sessioner och cookies på serversidan ger robust säkerhet och kontroll över sessionstillståndet och är ett utmärkt alternativ för traditionella webbapplikationer. Å andra sidan kan bearer tokens ge en förbättrad användarupplevelse och fungerar mycket bra i moderna SPA:er och mobila applikationer. Det finns också hybridmetoder som kombinerar tillstånd på serversidan och tokens för att utnyttja styrkorna och mildra de problem som är förknippade med båda metoderna.
I slutändan beror det bästa tillvägagångssättet för att implementera autentisering till stor del på specifika krav, säkerhetsöverväganden och applikationsarkitekturtypen. Det finns ingen enskild lösning som fungerar lika bra i alla fall.
Applikationstypen tillsammans med säkerhets- och användbarhetsöverväganden kommer också att spela en avgörande roll när man väljer det mest lämpliga OpenID Connect-flödet. Traditionella webbapplikationer med en komponent på serversidan kan säkert utnyttja Authorization Code Flow. Men inbyggda applikationer och rena SPA:er bör inte använda Authorization Code Flow utan att lägga till Proof Key of Code Exchange. För dessa applikationer är PKCE Flow det säkrare och rekommenderade alternativet. PKCE kan också vara fördelaktigt i andra typer av applikationsarkitekturer, t.ex. serverbaserade applikationer med SPA-klienter.
När OpenID Connect införlivas i en klientapplikation med befintlig autentiseringslogik rekommenderar vi att du använder Authorization Code Flow med en sessionsbaserad modell och PKCE Flow med den tokenbaserade modellen.
Det finns mycket mer att utforska, men vi hoppas att det här inlägget hjälper dig att fatta ett välgrundat beslut när du implementerar autentiseringsmekanismer i din applikation.
Trevlig kodning!

Varför är identifiering i samtal extra viktigt just nu?
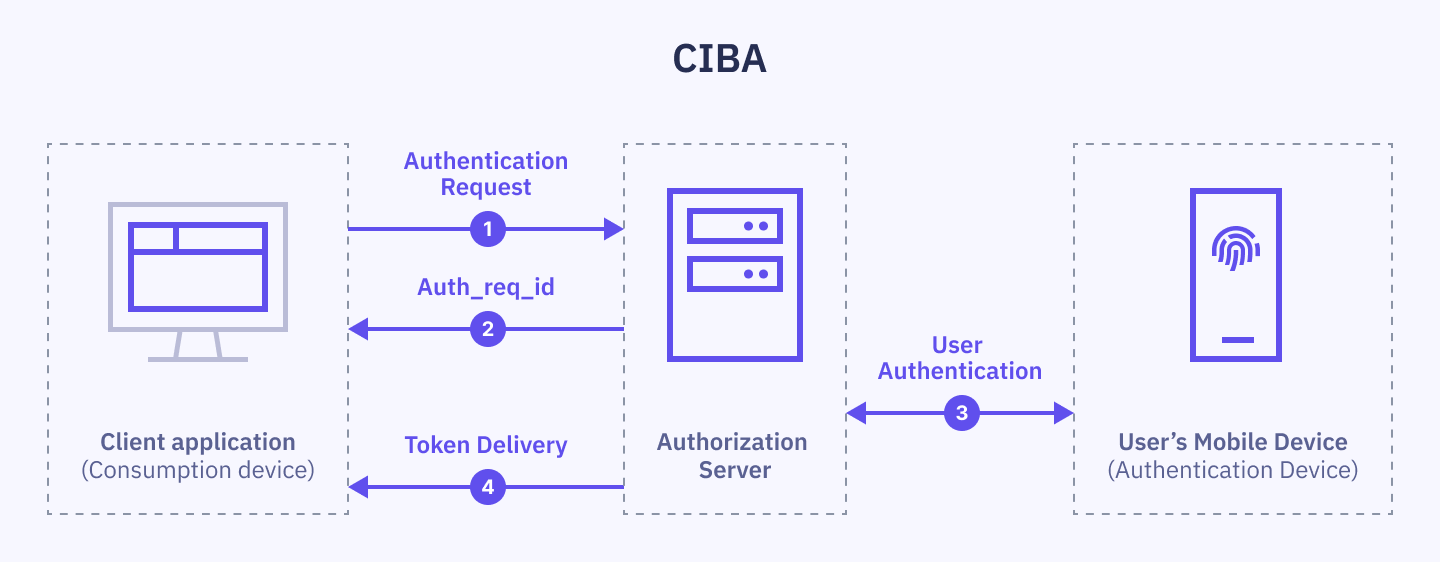
Hur fungerar Caller authentication egentligen?