
I dag er det nesten umulig å finne en webapplikasjon som ikke bruker en eller annen form for brukerautentisering. Sluttbrukerne må vanligvis gjennom en påloggingsprosess for å få tilgang til appens fulle funksjoner og beskyttede ressurser.
Men hvordan brukerautentisering implementeres, varierer avhengig av applikasjonens spesifikke krav og type, både når det gjelder tradisjonell brukernavn- og passordautentisering og den som implementeres via en føderert autentiseringsprotokoll, som for eksempel OpenID Connect.
I dette blogginnlegget gir vi en oversikt over øktbaserte og tokenbaserte implementeringsmetoder som brukes i tradisjonell autentisering. Vi belyser forskjellene mellom brukerøkter og tokener for å opprettholde autentiseringsstatus, og viser hvordan de passer til ulike applikasjonsarkitekturer.
I tillegg tar vi for oss de to primære autentiseringsflytene som er definert av OpenID Connect: Authorization Code Flow og Proof Key for Code Exchange (PKCE)-flyten. Vi diskuterer hvordan du velger riktig flyt i henhold til applikasjonstypen og innlemmer brukerinformasjonen som mottas fra OpenID Provider i en eksisterende autentiseringslogikk, enten økt- eller tokenbasert.
Hovedmålet er å identifisere viktige faktorer som må vurderes når man skal velge mellom øktbasert og tokenbasert autentisering. Vi vil også se nærmere på hvordan OpenID Connect-flyter effektivt kan integreres i en applikasjon med autentiseringsmekanismer som allerede er på plass.
1. Autentisering med brukerlegitimasjon
Brukerlegitimasjon er en vanlig måte for webapplikasjoner å verifisere brukeridentitet på. Med denne metoden oppgir brukerne en unik kombinasjon av brukernavn og passord for å få tilgang til beskyttede ressurser og data i applikasjonen. Autentiseringsprosessen innebærer at den oppgitte legitimasjonen valideres mot brukerdata som er lagret i applikasjonens database.
Fra registrering til autentisering: en mekanisme for lagring av en brukers autentiseringsstatus
La oss se på hva som skjer når en ny, uregistrert bruker samhandler med en applikasjon for første gang.
Ved denne første interaksjonen vil brukeren gå gjennom en registreringsprosess og oppgi brukernavn og passord på applikasjonens registreringsside. Når brukeren har sendt inn legitimasjonen sin, sendes denne informasjonen til serveren og lagres i applikasjonens database. Dette gjøres vanligvis via et API-endepunkt eller kode på serversiden som håndterer brukerregistreringsprosessen.
Neste gang den registrerte brukeren ber om tilgang til en beskyttet ressurs i applikasjonen, må vedkommende bevise at han eller hun har de nødvendige tilgangsrettighetene. For å unngå å be brukeren om påloggingsinformasjon ved hver forespørsel, er det nødvendig å implementere en mekanisme for å lagre brukerens autentiseringsstatus på tvers av flere HTTP-forespørsler. Dette skyldes HTTP-protokollens tilstandsløse natur, der hver forespørsel behandles uavhengig av hverandre og ikke har tilgang til informasjon fra tidligere forespørsler.
De to mekanismene som vanligvis brukes til dette formålet, er brukerøkter og bearer tokens. Utviklere velger mellom de to (eller implementerer en kombinasjon av begge) basert på hvilken type applikasjon de jobber med, hensynet til sikkerhet og brukervennlighet samt personlige preferanser.
Brukerøkter og informasjonskapsler
Begrepet "brukerøkt" refererer til en serie brukerinteraksjoner med applikasjonen innenfor en gitt tidsramme. En økt inneholder informasjon om autentiserte brukere og omfatter vanligvis en unik økt-ID, påloggings- og utløpstider og andre relevante data.
Økter genereres og lagres på serveren, slik at serveren kan holde oversikt over og autorisere brukerens forespørsler. Etter at en økt er opprettet, setter serveren en informasjonskapsel som inneholder økt-ID-en, og sender den til nettleseren. Når informasjonskapselen er lagret, vil nettleseren inkludere den i alle videre forespørsler inntil den utløper eller brukeren logger ut. Serveren bruker informasjonskapselen til å identifisere den aktuelle brukerøkten.
Brukersesjoner og informasjonskapsler har eksistert lenge og brukes fortsatt i stor utstrekning, spesielt i tradisjonelle webapplikasjoner der autentisering ofte er implementert på serversiden.
Bearer-tokens
En annen vanlig mekanisme for å administrere brukerautentisering er bruk av bærertokener. Det finnes andre tokenformater, men JSON Web Tokens (JWT) har blitt den rådende standarden for tokenbasert autentisering.
Et "token" er et kryptografisk signert stykke data som inneholder informasjon om den autentiserte brukeren og dennes tilgangstillatelser. Når en bruker logger seg på, oppretter serveren et token og sender det til klienten. Klienten lagrer deretter tokenet og inkluderer det i hver påfølgende forespørsel den sender til serveren. I motsetning til ved en brukerøkt trenger serveren bare å verifisere tokenets gyldighet i stedet for å lagre det i en database. Dette er mulig fordi tokenet i seg selv inneholder all informasjonen som trengs for å bevise at det er gyldig.
Med tokenbasert autentisering trenger ikke serveren å lagre hver enkelt brukers autentiseringsstatus, noe som til syvende og sist reduserer mengden status som må lagres på serveren.
Bearer-tokens er et populært valg for moderne Single-Page Applications (SPA), der autentisering ofte gjøres på klientsiden og der hastighet, brukeropplevelse og skalerbarhet ofte prioriteres.
Med denne forståelsen av økter og tokens kan vi gå videre til å skape et mer komplett bilde av øktbaserte og tokenbaserte autentiseringsflyter.
Øktbasert autentisering
Øktbasert autentisering fungerer på en tilstandsbasert måte. Det betyr at det må opprettholdes en sesjonsregistrering både på server- og klientsiden. Serveren holder oversikt over aktive brukerøkter og lagrer dem i minnet eller i en database, og nettleseren har økt-ID-en i en informasjonskapsel.
Flyten i den sesjonsbaserte autentiseringen er som følger:
- Brukeren taster inn påloggingsinformasjonen sin i applikasjonens påloggingsskjema. Når skjemaet er sendt inn, sender nettleseren en POST-forespørsel til serveren med brukeren autentiseringsopplysninger.
- Serveren verifiserer brukerens legitimasjon, f.eks. ved å sjekke den mot en database over autoriserte brukere. Hvis legitimasjonen stemmer overens, oppretter serveren en brukerøkt med en unik økt-ID og lagrer den i en database.
- Serveren returnerer deretter økt-ID-en til nettleseren, vanligvis ved å inkludere en Set-Cookie header i svaret som inneholder en informasjonskapsel med økt-ID-en.
- Informasjonskapselen med økt-ID-en lagres i nettleseren.
- Fra nå av vil nettleseren inkludere en informasjonskapsel med økt-ID i hver forespørsel som sendes til serveren hver gang denne brukeren ber om en side.
- Serveren mottar forespørselen og kontrollerer økt-ID-en.
- Hvis økt-ID-en er gyldig, svarer serveren med den forespurte ressursen.
- Når brukeren logger ut, ødelegges økten på serveren, og øktinformasjonskapselen slettes fra nettleseren.
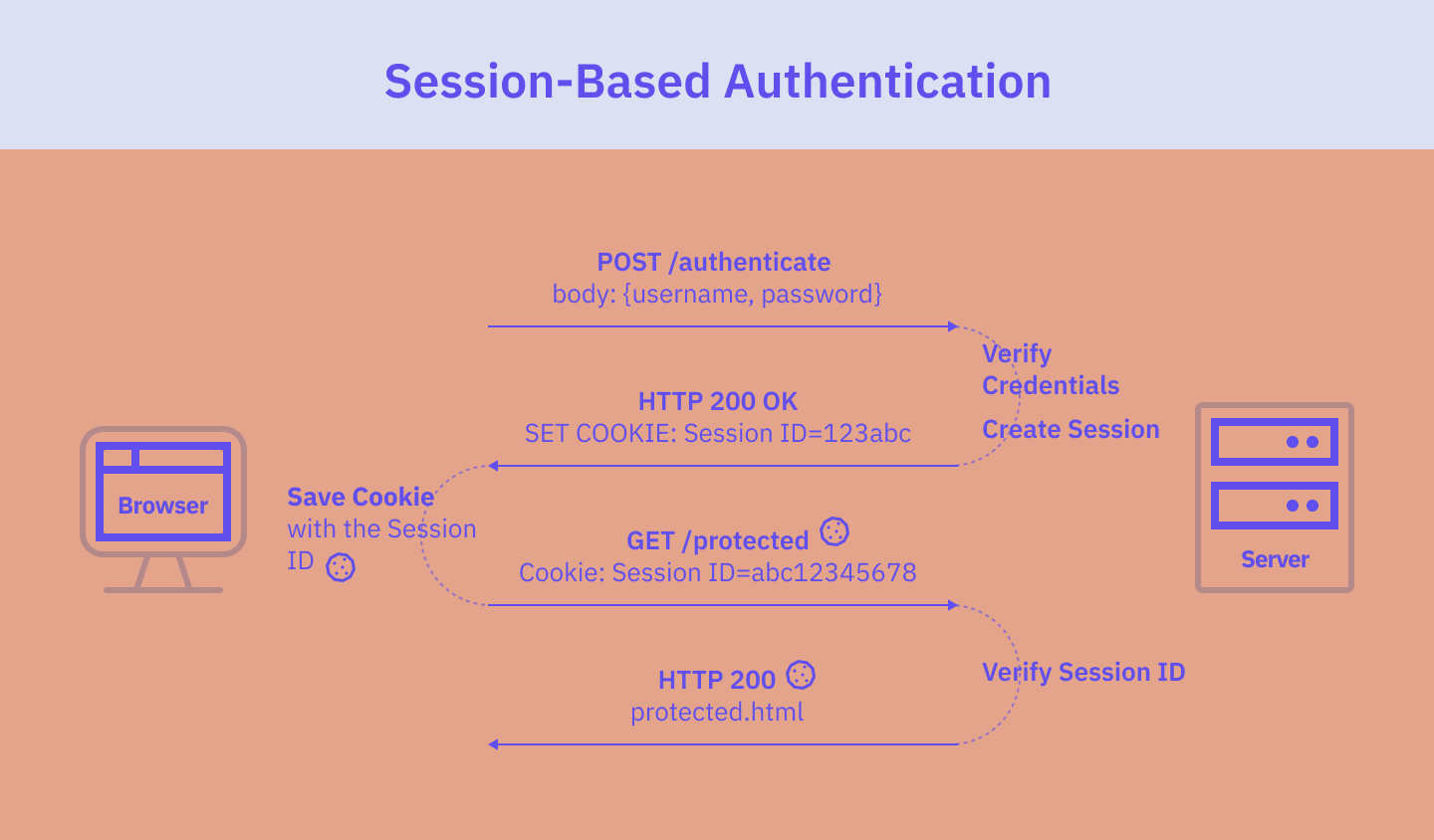
Øktbasert autentisering brukes fortsatt ofte og har sine fordeler. Det fungerer veldig bra i en tradisjonell server/nettleser-modell, men er kanskje ikke ideelt for moderne webapplikasjoner som krever hyppig datautveksling mellom klienten og serveren.
Token-basert autentisering
Med fremveksten av Single-Page Applications og API-er har tokenbasert autentisering blitt stadig mer populært. Denne tilnærmingen baserer seg på bruk av tokens for brukerautentisering og fungerer på en tilstandsløs måte. I motsetning til øktbasert autentisering trenger ikke serveren å holde oversikt over utstedte tokens eller påloggede brukere. I stedet kontrollerer serveren bare gyldigheten til tokens den mottar.
Autentiseringsflyten for tokenbasert autentisering er som følger:
- Brukeren taster inn påloggingsinformasjonen sin i applikasjonens påloggingsskjema. Klienten sender brukerens legitimasjon til serveren i en POST-forespørsel.
- Serveren verifiserer brukerens legitimasjon ved å sjekke den mot en database og genererer et bærertoken. Bærer-tokenet inneholder informasjon som brukerens identitet og eventuelle relevante tillatelser eller roller.
- Serveren sender tokenet tilbake til klienten.
- Klienten mottar tokenet og lagrer det lokalt for bruk ved senere forespørsler til beskyttede ressurser. I nettleserbaserte applikasjoner lagres tokenet vanligvis i localStorage eller sessionStorage. I native mobilapplikasjoner lagres det i den aktuelle lagringen som tilbys av operativsystemet.
- Klienten sender tokenet sammen med hver påfølgende forespørsel til serveren, vanligvis i Authorization-overskriften i HTTP-forespørselen:
Authorization: Bearer <token> - Serveren kontrollerer tokenets gyldighet og autorisasjon ved hver forespørsel.
- Hvis tokenet er gyldig, autoriserer serveren forespørselen.
- Når en bruker logger ut, ødelegges tokenet på klientsiden. Ingen interaksjon med serveren er nødvendig.
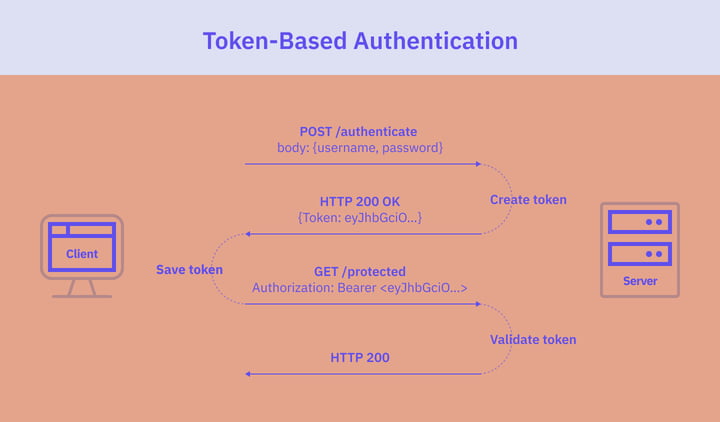
Tokenbasert autentisering har flere fordeler, blant annet en jevnere brukeropplevelse, redusert arbeidsbelastning på serveren og bedre skalerbarhet og ytelse på grunn av sin tilstandsløse natur. Det er imidlertid noen sikkerhetsproblemer knyttet til bruken av tokens, med tanke på de sensitive dataene de inneholder.
Velge riktig tilnærming
Bruken av økter kontra tokens i brukerautentisering er et omdiskutert tema.
Noen utviklere foretrekker sesjoner og informasjonskapsler på serversiden: en pålitelig metode som passer godt inn i den tradisjonelle arkitekturen for webapplikasjoner, som fortsatt er utbredt. Andre velger tokens, ettersom de kan gi en bedre brukeropplevelse, bidrar til å unngå kompleksiteten rundt informasjonskapsler på tvers av domener og fungerer utmerket i moderne SPA-er og mobilapplikasjoner.
Denne artikkelen gir en uttømmende oppsummering av fordeler og vurderinger når du skal velge mellom økt- og tokenbasert autentisering.
En annen mulig tilnærming er en kombinasjon av sesjoner på serversiden og tokens. En bruker kan for eksempel autentiseres via et bærertoken på klientsiden, mens serveren verifiserer brukerens autentiseringsstatus med en økt på serversiden.
Alt i alt finnes det ingen universelle regler for valg av den mest hensiktsmessige autentiseringsimplementeringen. Valget vil i stor grad avhenge av de spesifikke behovene og kravene til den enkelte applikasjonen og applikasjonsarkitekturen. Hvis de implementeres med beste sikkerhetspraksis og brukervennlighetskrav i tankene, kan både økter og tokens (eller en kombinasjon av disse) gi tilstrekkelig beskyttelse og en brukervennlig autentiseringsmekanisme.
2. Autentisering med OpenID Connect
Den fødererte identitetsmodellen er et overbevisende alternativ til tradisjonell autentisering med brukernavn og passord.
Ved å benytte en føderert autentiseringsprotokoll, som OpenID Connect (OIDC), kan utviklere effektivisere autentiseringsprosessen og gi brukerne en velkjent og praktisk måte å få tilgang til applikasjoner på ved å logge inn med en ekstern identitetsleverandør. Brukerne kan for eksempel logge på med sine eksisterende Google- eller Facebook-kontoer, eller med nasjonale eID-er.
OpenID Connect: velge mellom Authorization Code Flow og PKCE
OpenID Connect definerer flere autentiseringsflyter som beskriver hvordan klientapplikasjonen skal samhandle med en OpenID Provider.
La oss sammenligne de to OIDC-flytene som er mye brukt og anbefalt for brukerautentisering: Authorization Code Flow og PKCE-flyten (Proof Key for Code Exchange).
Begge innebærer at brukerne deler legitimasjonen sin med en OpenID Provider. I begge tilfeller utsteder OpenID Provider et token som representerer brukeren. De to flytene er imidlertid utformet for å fungere best i ulike typer applikasjoner.
Autorisasjonskodeflyten er beregnet på tradisjonelle webapplikasjoner som har en komponent på serversiden og kan lagre en klienthemmelighet på en sikker måte. Denne flyten innebærer å utveksle autorisasjonskoden fra OpenID Provider mot et token. For å utveksle kode mot token må klientapplikasjonen presentere autorisasjonskoden sammen med en klienthemmelighet for å be om et token. Klienthemmeligheten er en konfidensiell identifikator som bare er kjent for klientapplikasjonen og OpenID Provider.
PKCE-flyten (eller Authorization Code Flow + PKCE) er en utvidelse av Authorization Code Flow og krever også kode-for-token-utveksling. Men i stedet for en klienthemmelighet introduserer PKCE-flyten en kodeverifiserer (en engangshemmelighet som opprettes av klientapplikasjonen, og som kan verifiseres av OpenID Provider) og en kodeutfordring (en hashet og kodet versjon av kodeverifisereren). Under utvekslingen av kode for kode presenterer klientapplikasjonen autorisasjonskoden sammen med kodeverifikatoren. OpenID Provider vil bare gå videre med tokenutvekslingen hvis denne kodeverifikatoren samsvarer med den opprinnelige kodeutfordringen som ble opprettet av klientapplikasjonen. Kombinasjonen av kodeutfordringen og kodeverifikatoren i PKCE Flow sikrer at selv om autorisasjonskoden blir fanget opp under overføring, kan den ikke byttes mot et token av en uautorisert part.
PKCE Flow er spesielt utviklet for å autentisere brukere av native- eller mobilapplikasjoner. Det regnes som beste praksis i native applikasjoner og Single-Page-applikasjoner som ikke har en måte å lagre en klienthemmelighet på. PKCE Flow kan også være et godt valg for andre typer applikasjoner, fordi det kan skape en jevnere brukeropplevelse i visse situasjoner. I applikasjoner som for eksempel har en SPA-klient koblet til en server, fungerer PKCE Flow best fordi autentiseringsprosessen løses på klientsiden.
Nå som vi har sett hvordan de to OIDC-godkjenningsflytene egner seg best for ulike applikasjonsarkitekturer, skal vi se nærmere på hvordan de kan integreres i en klientapplikasjon som allerede har autentiseringslogikk på plass.
Kort sagt: For øktbasert autentisering anbefaler vi å bruke Authorization Code Flow. Denne flyten passer godt til tradisjonell webapplikasjonsarkitektur og gir et høyt sikkerhetsnivå hvis applikasjonen har en komponent på serversiden som kan lagre en klienthemmelighet på en sikker måte.
PKCE-flyten er derimot et logisk valg for den tokenbaserte autentiseringsmodellen på klientsiden, som ofte implementeres av native applikasjoner eller SPA-er. PKCE Flow gir ekstra sikkerhet for applikasjoner som enten ikke har en sikker måte å oppbevare en klienthemmelighet på, eller som har spesifikke krav knyttet til brukeropplevelsen.
Den korte tabellen nedenfor gir et sammendrag:
|
Øktbasert autentisering |
Token-basert autentisering |
Hybrid tilnærming som kombinerer sesjoner og tokens |
|
Autorisasjonskodeflyt |
PKCE Flow anbefales |
PKCE Flow mest sannsynlig, men det er mulig å bruke begge deler |
Koble JWT-utdataene til et bærertoken eller en brukerøkt
Når OIDC-flyten er fullført og klientapplikasjonen mottar JWT-tokenet fra OpenID Provider, kan den enten bruke tokenet direkte eller trekke ut og bruke informasjonen i JWT-påstandene. Måten klientapplikasjonen implementerer autentisering på, avgjør hvordan JWT-utdataene håndteres.
Øktbasert autentisering og OIDC
Som nevnt innebærer øktbasert autentisering at det genereres en unik økt-ID i applikasjonen og lagres i en database.
Når du utnytter brukerinformasjonen som er innhentet gjennom OIDC-autorisasjon, kan du lagre JWT-en i brukerøkten. Alternativt kan du trekke ut spesifikk informasjon fra JWT-en og koble den til økten for fremtidig referanse.
I begge tilfeller vil økt-ID-en brukes til å knytte senere forespørsler fra den samme brukeren til den lagrede øktinformasjonen.
Tokenbasert autentisering og OIDC
Med tokenbasert autentisering kan du enten bruke JWT-en utstedt av OpenID Provider som ditt eget bærertoken, eller la backend generere et nytt bærertoken basert på JWT-en mottatt fra OIDC-autentisering. Det første alternativet er det vanligste, men det finnes noen situasjoner der det er mer hensiktsmessig å generere et nytt bærertoken. For eksempel:
- Hvis klientapplikasjonen allerede er avhengig av et bestemt bærertokenformat for sin eksisterende autentiseringslogikk, kan det å utlede et nytt bærertoken bidra til å sikre kompatibilitet.
- Hvis applikasjonen samhandler med eksterne tjenester og API-er som har spesifikke krav til tokenformatet, må du utstede et nytt bærertoken som er i tråd med disse.
- Utstedelse av et nytt bærertoken gir mer fleksibilitet, slik at du kan tilpasse tokenet etter applikasjonens behov (f.eks. ved å inkludere ytterligere krav eller metadata).
- Ved å generere et nytt bærertoken får du mer kontroll over tokenets livssyklus, og det kan være nødvendig hvis du har spesifikke krav til utløp og tilbakekalling av tokenet.
Oppsummering
Når du implementerer brukerautentisering, kan utviklere velge mellom øktbaserte og tokenbaserte tilnærminger.
Sesjoner og informasjonskapsler på serversiden gir robust sikkerhet og kontroll over øktstatus, og er et godt alternativ for tradisjonelle webapplikasjoner. På den annen side kan tokener gi en bedre brukeropplevelse og fungere svært godt i moderne SPA-er og mobilapplikasjoner. Det finnes også hybride tilnærminger som kombinerer serverside-tilstand og tokens for å utnytte styrkene og redusere problemene som er forbundet med begge metodene.
Til syvende og sist vil den beste tilnærmingen for å implementere autentisering i stor grad avhenge av spesifikke krav, sikkerhetshensyn og typen applikasjonsarkitektur. Det finnes ikke én enkelt løsning som fungerer like godt i alle tilfeller.
Applikasjonstypen, sammen med hensynet til sikkerhet og brukervennlighet, vil også spille en avgjørende rolle når man skal velge den mest egnede OpenID Connect-flyten. Tradisjonelle webapplikasjoner med en komponent på serversiden kan trygt utnytte Authorization Code Flow. Men native applikasjoner og rene SPA-er bør ikke bruke Authorization Code Flow uten å legge til Proof Key of Code Exchange. For disse applikasjonene er PKCE Flow det sikreste og anbefalte alternativet. PKCE kan også være nyttig i andre typer applikasjonsarkitekturer, for eksempel serverbaserte applikasjoner med SPA-klienter.
Når OpenID Connect er innlemmet i en klientapplikasjon med eksisterende autentiseringslogikk, anbefaler vi å bruke Authorization Code Flow med en øktbasert modell og PKCE Flow med den tokenbaserte modellen.
Selv om det er mye mer å utforske, håper vi at dette innlegget vil hjelpe deg med å ta en informert beslutning når du skal implementere autentiseringsmekanismer i applikasjonen din.
God fornøyelse med kodingen!
-2.png)
Sikker Samtale: Idura lancerer ny identitetsløsning med MobilePay

Samtaleautentisering vs. stemmebiometri
